Python爬虫的N种姿势
问题的由来
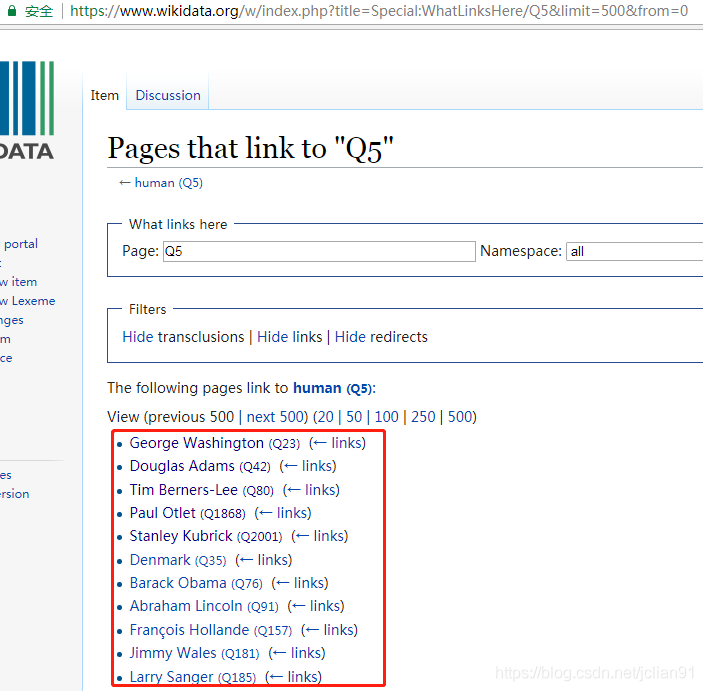
前几天,在微信公众号(Python爬虫及算法)上有个人问了笔者一个问题,如何利用爬虫来实现如下的需求,需要爬取的网页如下(网址为:https://www.wikidata.org/w/index.php?title=Special:WhatLinksHere/Q5&limit=500&from=0):
我们的需求为爬取红色框框内的名人(有500条记录,图片只展示了一部分)的 名字以及其介绍,关于其介绍,点击该名人的名字即可,如下图:
这就意味着我们需要爬取500个这样的页面,即500个HTTP请求(暂且这么认为吧),然后需要提取这些网页中的名字和描述,当然有些不是名人,也没有描述,我们可以跳过。最后,这些网页的网址在第一页中的名人后面可以找到,如George Washington的网页后缀为Q23. 爬虫的需求大概就是这样。
爬虫的4种姿势 首先,分析来爬虫的思路:先在第一个网页(https://www.wikidata.org/w/index.php?title=Special:WhatLinksHere/Q5&limit=500& ...
python三步实现人脸识别
Face Recognition软件包
这是世界上最简单的人脸识别库了。你可以通过Python引用或者命令行的形式使用它,来管理和识别人脸。
该软件包使用dlib中最先进的人脸识别深度学习算法,使得识别准确率在《Labled Faces in the world》测试基准下达到了99.38%。
它同时提供了一个叫face_recognition的命令行工具,以便你可以用命令行对一个文件夹中的图片进行识别操作。
特性
在图片中识别人脸
找到图片中所有的人脸
找到并操作图片中的脸部特征
获得图片中人类眼睛、鼻子、嘴、下巴的位置和轮廓
找到脸部特征有很多超级有用的应用场景,当然你也可以把它用在最显而易见的功能上:美颜功能(就像美图秀秀那样)。
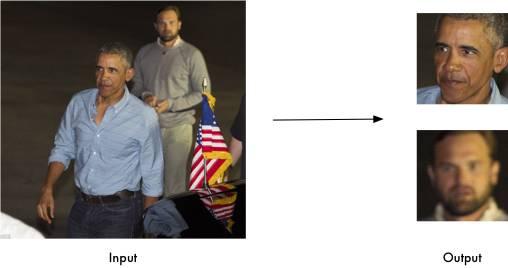
鉴定图片中的脸
识别图片中的人是谁。
你甚至可以用这个软件包做人脸的实时识别。
这里有一个实时识别的例子:
1https://github.com/ageitgey/face_recognition/blob/master/examples/facerec_from_webcam_faster.py
安装
环境要求
Python3.3 ...

【算法】超详细的遗传算法(Genetic Algorithm)解析
00 目录
遗传算法定义
生物学术语
问题导入
大体实现
具体细节
代码实现
01 什么是遗传算法?1.1 遗传算法的科学定义遗传算法(Genetic Algorithm, GA)是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。
其主要特点是直接对结构对象进行操作,不存在求导和函数连续性的限定;具有内在的隐并行性和更好的全局寻优能力;采用概率化的寻优方法,不需要确定的规则就能自动获取和指导优化的搜索空间,自适应地调整搜索方向。
遗传算法以一种群体中的所有个体为对象,并利用随机化技术指导对一个被编码的参数空间进行高效搜索。其中,选择、交叉和变异构成了遗传算法的遗传操作;参数编码、初始群体的设定、适应度函数的设计、遗传操作设计、控制参数设定五个要素组成了遗传算法的核心内容。
1.2 遗传算法的执行过程(参照百度百科)遗传算法是从代表问题可能潜在的解集的一个种群(population)开始的,而一个种群则由经过基因(gene)编码的一定数目的个体(individual)组成。每个个体实际上是染色体(chromosome)带有 ...
人工智能神经网络四种算法
人工神经网络的许多算法已在智能信息处理系统中获得广泛采用,尤为突出是是以下4种算法:ART网络、LVQ网络、Kohonen网络Hopfield网络,下面就具体介绍一下这这四种算法:
1.自适应谐振理论(ART)网络
自适应谐振理论(ART)网络具有不同的方案。一个ART-1网络含有两层一个输入层和一个输出层。这两层完全互连,该连接沿着正向(自底向上)和反馈(自顶向下)两个方向进行。
当ART-1网络在工作时,其训练是连续进行的,且包括下列算法步骤:
(1)对于所有输出神经元,如果一个输出神经元的全部警戒权值均置为1,则称为独立神经元,因为它不被指定表示任何模式类型。
(2)给出一个新的输入模式x。
(3)使所有的输出神经元能够参加激发竞争。
(4)从竞争神经元中找到获胜的输出神经元,即这个神经元的x·W值为最大;在开始训练时或不存在更好的输出神经元时,优胜神经元可能是个独立神经元。
(5)检查该输入模式x是否与获胜神经元的警戒矢量V足够相似。
(6)如果r≥p,即存在谐振,则转向步骤(7);否则,使获胜神经元暂时无力进一步竞争,并转向步骤(4),重复这一过程直至不存在更多的有能力的神经 ...

使用python来访问Hadoop HDFS存储实现文件的操作
使用python来访问Hadoop HDFS存储实现文件的操作在调试环境下,咱们用hadoop提供的shell接口测试增加删除查看,但是不利于复杂的逻辑编程
查看文件内容
用python访问hdfs是个很头疼的事情。。。。
这个是pyhdfs的库
1234567import pyhdfsfs = pyhdfs.connect("192.168.1.1", 9000)pyhdfs.get(fs, "/rui/111", "/var/111")f = pyhdfs.open(fs, "/test/xxx", "w")pyhdfs.write(fs, f, "fuck\0gfw\n")pyhdfs.close(fs, f)pyhdfs.disconnect(fs)
pyhdfs的安装过程很吐血
1234567svn checkout http://libpyhdfs.googlecode.com/svn/trunk/ libpyhdfscd libpyhdfscp ...
决策树中结点的特征选择方法
一、信息增益 信息增益用在ID3决策树中,信息增益是依据熵的变化值来决定的值。
熵:随机变量不确定性大小的度量。熵越大,变量的不确定性就越大。
熵的公式表示:
X的概率分布为P(x=xi) = pi, i=1,2,3…(x可能的取值),随机变量X熵为,并且0log0=1。
条件熵:H(Y|X)表示在随机变量X的条件下随机变量Y的不确定性。
在决策树中,Y即是数据集,X即是某个特征,即条件熵就是数据集在特征A划分条件下的熵。
信息增益:数据集D的熵H(D)与特征A给定条件下D的条件熵H(D|A)之差。g(D|A)=H(D)-H(D|A)
因此根据信息增益决策划分节点时特征选择方法是:对训练数据集D,计算其每隔特征的信息增益,并比较它们的大小,选择信息增益最大的特征。
二、信息增益比 以信息增益作为划分数据集的特征,存在偏向于选择去取值较多的特征的问题,这时候可以使用信息增益比对这一问题进行修正。C4.5决策树正是基于信息增益比进行特征的选择进行结点的分割。
信息增益比定义:特征A对于训练集D的信息增益比定义为信息增 ...
无监督学习
目录
1 关于机器学习
2 sklearn库中的标准数据集及基本功能
2.1 标准数据集
2.2 sklearn库的基本功能
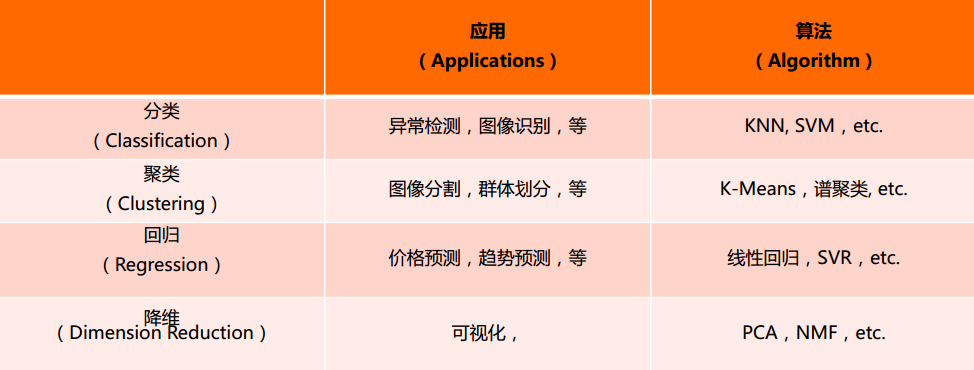
3 关于无监督学习
4 K-means方法及应用
5 DBSCAN方法及应用
6 PCA方法及其应用
7 NMF方法及其实例
8 基于聚类的“图像分割”
正文
1 关于机器学习 机器学习是实现人工智能的手段, 其主要研究内容是如何利用数据或经验进行学习, 改善具体算法的性能
多领域交叉, 涉及概率论、统计学, 算法复杂度理论等多门学科
广泛应用于网络搜索、垃圾邮件过滤、推荐系统、广告投放、信用评价、欺诈检测、股票交易和医疗诊断等应用 机器学习的分类
监督学习 (Supervised Learning)
从给定的数据集中学习出一个函数, 当新的数据到来时, 可以根据这个函数预测结果, 训练集通常由人工标注
无监督学习 (Unsupervised Learning)
相较于监督学习, 没有人工标注
强化学习(Reinforcement Learning,增强学习)
通过观察通 ...

深入浅出--梯度下降法及其实现
梯度下降的场景假设
梯度
梯度下降算法的数学解释
梯度下降算法的实例
梯度下降算法的实现
Further reading
本文将从一个下山的场景开始,先提出梯度下降算法的基本思想,进而从数学上解释梯度下降算法的原理,最后实现一个简单的梯度下降算法的实例!
梯度下降的场景假设
梯度下降法的基本思想可以类比为一个下山的过程。假设这样一个场景:一个人被困在山上,需要从山上下来(i.e. 找到山的最低点,也就是山谷)。但此时山上的浓雾很大,导致可视度很低。因此,下山的路径就无法确定,他必须利用自己周围的信息去找到下山的路径。这个时候,他就可以利用梯度下降算法来帮助自己下山。具体来说就是,以他当前的所处的位置为基准,寻找这个位置最陡峭的地方,然后朝着山的高度下降的地方走,同理,如果我们的目标是上山,也就是爬到山顶,那么此时应该是朝着最陡峭的方向往上走。然后每走一段距离,都反复采用同一个方法,最后就能成功的抵达山谷。
image.png
我们同时可以假设这座山最陡峭的地方是无法通过肉眼立马观察出来的,而是需要一个复杂的工具来测量,同时,这个人此时正好拥有测量出最陡峭方向的能力。所以,此人 ...
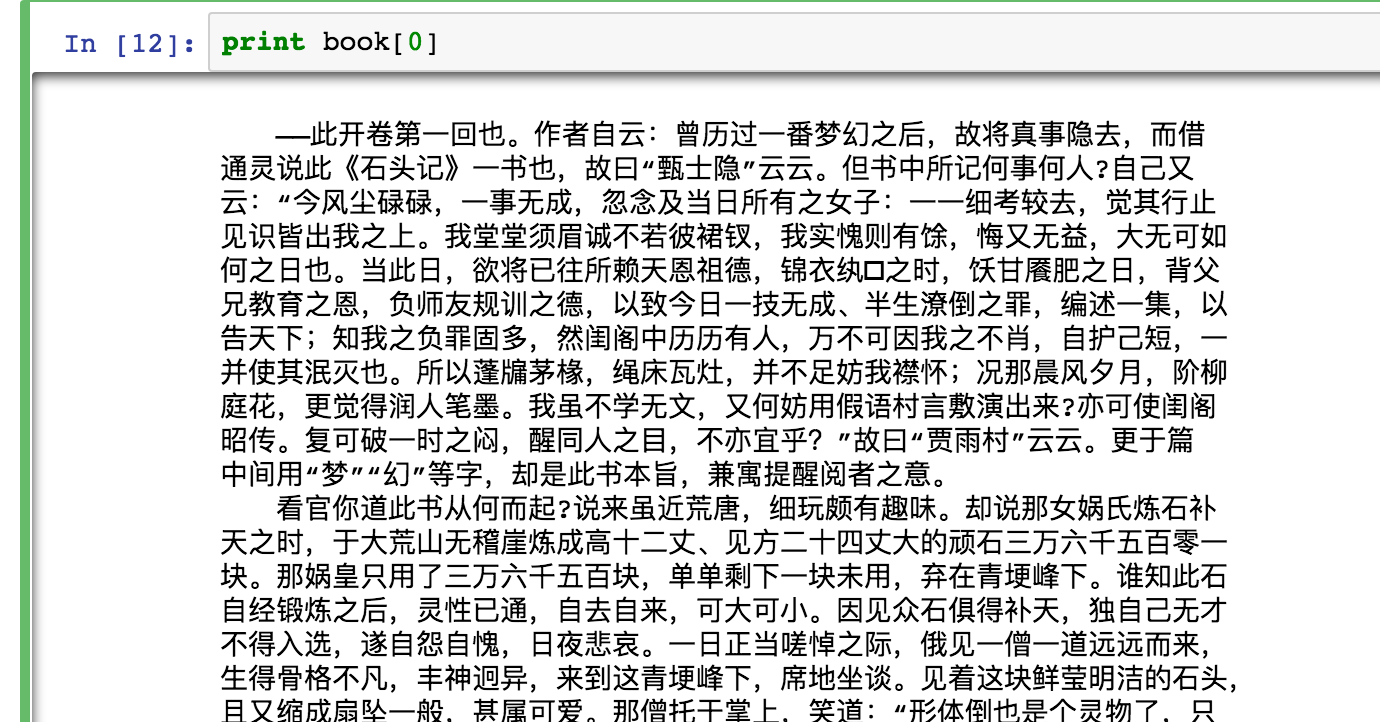
重做红楼梦的数据分析-判断前80回后40回是否一个人写的
重做红楼梦的数据分析-判断前80回后40回是否一个人写的红楼梦的数据分析已经有许多人做过,结论也各不相同。我在知乎上看到两篇帖子:\1. [通过数据挖掘能分析《红楼梦》各回的真伪吗?](https://www.zhihu.com/question/19768898 智慧思特的回答)\2. 用机器学习判定红楼梦后40回是否曹雪芹所写觉得很有意思,于是用自己的方法重做了一次
环境配置:我主要使用的编程环境是Jupyter Notebook 4.2.1,因为可以调整每一个代码块,方便纠错什么的。然后我们得用到一个中文分词工具 - Jieba, 是由百度工程师Sun Junyi开发的之后我们还得用到一些做机器学习/数据挖掘的标准包:numpy, matplotlib 和 sklearn
数据准备:用爬虫思想,我去这个网站扒下来红楼梦全集,然后剪掉中间所有的换行符,使得每一回只占文档中的一行。这样的话,方便接下来读取。
直接上代码:一、导入各种需要的包
123456789101112131415161718192021# -*-coding:utf-8 -*-import urllibimpor ...
FFmpeg实战 保存网络流
今天我们开始正式进入FFmpeg的篇章,FFmpeg作为著名的开源框架,可以生成用于处理多媒体框架的库和程序,是音视频界内的圣经,市面上直播开发99%都是基于FFmpeg来开发的,这足以证明FFmpeg的强大。关于FFmpeg的源码和官方文档可以去FFmpeg下载源码和编译好的库。 闲话不多说,下面就开始今天的主要内容,FFmpeg保存网络流到本地 直播不像点播,当我们看到想看的内容时,我们不能倒退回去,但是我们可以保存直播流为本地文件,这样我们想看随时都可以。
保存网络流的流程主要有以下步骤: 第一步:注册所有的组件(编解码、滤镜特效处理库、封装格式处理库、工具库、音频采样数据格式转换库、视频像素数据格式转换等等…) 第二步:获取视频流的封装信息,查找视频和音频流的位置 第三步:查找视频和音频解码器id,根据解码器id打开解码器 第四步:创建输出流并拷贝流上下文信息 第五步:循环读取网络流,解码packet并写入本地 第六步:关闭解码器释放内存
源码12345678910111213141516171819202122232425262728293031323334 ...